球路难测准:羽毛球飞行过程中受空气动力学影响显著,姿态易产生不规则摆动,轨迹不是标准的抛物线。用传统方法预测落点,误差经常超过20厘米,这对需要实现精准定位的机器人击球任务,此类误差已经超出可容错范围。
动作难学对:机器人击球动作的学习依赖于试错过程,但由于仅在成功击球且落点准确时才能获得有效反馈,奖励信号极为稀疏。这种稀疏性容易导致策略陷入局部最优,例如,机器人可能仅学会提前静止于某位置等待来球,而非主动规划迎击轨迹,从而显著降低学习效率与策略质量。
硬件难跟上:羽毛球高速运动的特点对机器人动态性能提出极高要求,机器人在关节速度、加速度等方面存在物理约束,因此,即使在仿真环境中训练出高性能策略,也常因硬件动态能力不足而无法在真实系统中复现,导致显著的“仿真—现实”性能落差。
这些挑战相互关联,共同构成机器人羽毛球系统的技术瓶颈。本研究旨在通过集成化方法,协同解决轨迹预测、策略学习和执行控制问题,提升系统整体性能。
部署FZMotion Swift30A光学动捕相机
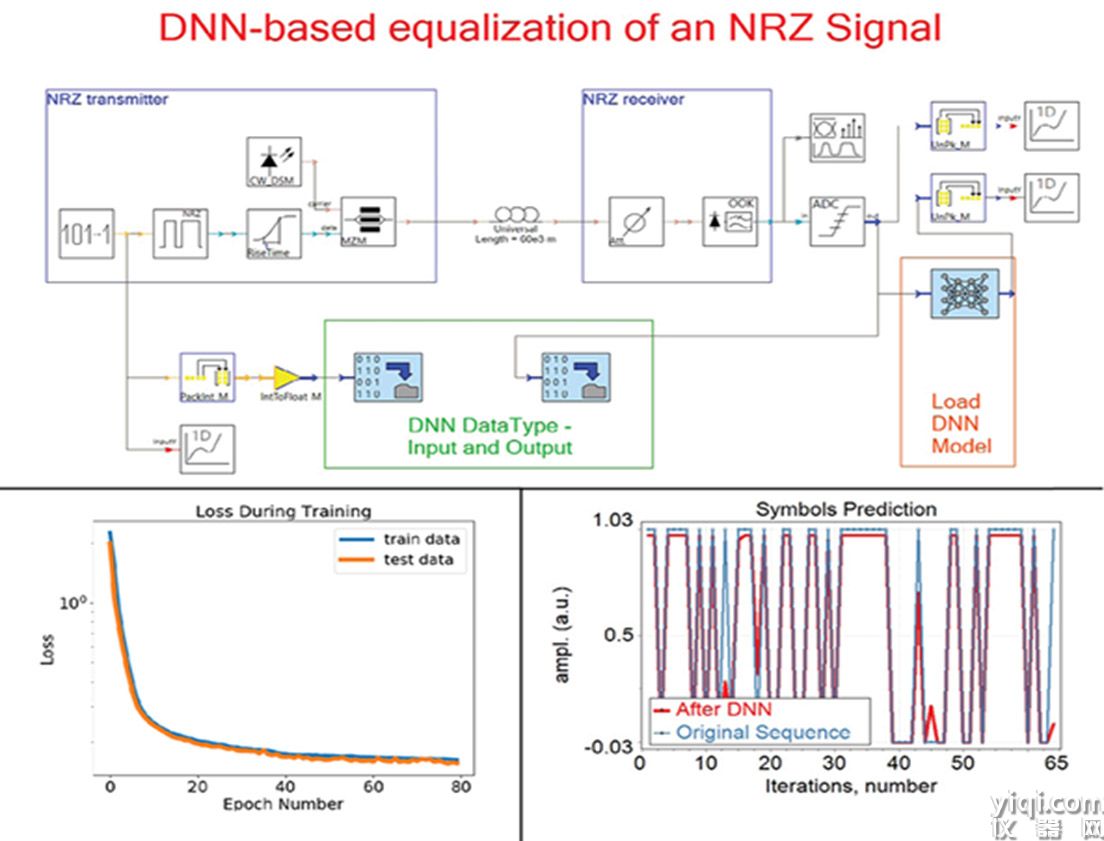
浙江大学王宏涛教授团队在机器人领域期刊《Frontiers in Neurorobotics》上发表论文《Imitation-relaxation reinforcement learning for sparse badminton strikes via dynamic trajectory generation》,针对机械臂打羽毛球任务中存在的动力学非线性、控制实时性要求高、强化学习奖励稀疏三大挑战-提出了一种DTG-IRRL的羽毛球击球学习框架:将模仿松弛强化学习(Imitation-Relaxation Reinforcement Learning,IRRL)与动态轨迹生成(Dynamic Trajectory Generation,IRRL)相结合;在实物平台上,框架实现了零样本迁移,实验结果表明其击球成功率可达90%,落点精度达70%,并实现持续多回合人机对抗;使用UR5机器人进行的跨平台验证表明了该框架的通用性,同时也突显了球拍运动中机械臂高动态性能的要求。
论文原文链接地址:
Frontiers | Imitation-relaxation reinforcement learning for sparse badminton strikes via dynamic trajectory generation
本研究的创新在于:提出动态轨迹生成与模仿-松弛强化学习融合框架,提升稀疏奖励任务性能;通过奖励可视化阐明其缓解局部收敛的机理;并在实物平台完成零样本迁移验证。
1. 提出的一种学习框架(DTG-IRRL),该框架融合了模仿松弛和强化学习以及动态轨迹生成,从而实现了更快的收敛速度和更高的成功率和落点精度。
2. 对特定超平面内奖励分布的分析直观地展示了该框架在缓解因奖励稀疏导致的局部收敛缓慢问题方面的有效性。
3. 在硬件平台上实现了零样本迁移,击中率达到 90%,落点准确率达到 70%,同时能够实现持续数十回合的人机交互击打。
通过仿真与实物实验结合的体系对DTG-IRRL框架进行了系统验证,采用现有机械臂硬件系统,基于
IROS 2025 | 上交大提出ICF-DO:一种面向舵轮机器人的鲁棒分布式里程计
IROS 2025 | 清华大学半分布式相对定位框架:解决空地协同中有限带宽条件下的准确、灵活、高效的相对定位
全部评论(0条)
 虚拟摄像机- Insight VCS
虚拟摄像机- Insight VCS
报价:面议 已咨询 1716次
 低照度星光抓拍机-SQ系列
低照度星光抓拍机-SQ系列
报价:面议 已咨询 1736次
 高清智能交通一体机-SQ系列
高清智能交通一体机-SQ系列
报价:面议 已咨询 1655次
 CMOS高清交通抓拍机—SQ系列
CMOS高清交通抓拍机—SQ系列
报价:面议 已咨询 1531次
 TOF相机-SR系列
TOF相机-SR系列
报价:面议 已咨询 1570次
 多光谱相机-2CCD系列
多光谱相机-2CCD系列
报价:面议 已咨询 1699次
 X-RayCMOS平板探测Shad-o-box 系列
X-RayCMOS平板探测Shad-o-box 系列
报价:面议 已咨询 1824次
 X-Ray面阵CMOS平板-Xineos系列
X-Ray面阵CMOS平板-Xineos系列
报价:面议 已咨询 1646次









①本文由仪器网入驻的作者或注册的会员撰写并发布,观点仅代表作者本人,不代表仪器网立场。若内容侵犯到您的合法权益,请及时告诉,我们立即通知作者,并马上删除。
②凡本网注明"来源:仪器网"的所有作品,版权均属于仪器网,转载时须经本网同意,并请注明仪器网(www.yiqi.com)。
③本网转载并注明来源的作品,目的在于传递更多信息,并不代表本网赞同其观点或证实其内容的真实性,不承担此类作品侵权行为的直接责任及连带责任。其他媒体、网站或个人从本网转载时,必须保留本网注明的作品来源,并自负版权等法律责任。
④若本站内容侵犯到您的合法权益,请及时告诉,我们马上修改或删除。邮箱:hezou_yiqi
















参与评论
登录后参与评论